To train ![]() ROBIN, we curate
ROBIN, we curate ![]() SVG, a synthetic scene graph dataset by completing the missing relations of selected objects in existing scene graphs using a teacher MLM and a carefully designed filtering process to ensure high-quality.
To generate more accurate and rich scene graphs at scale for any image, we introduce SG-EDIT: a self-distillation framework where GPT-4o further refines
SVG, a synthetic scene graph dataset by completing the missing relations of selected objects in existing scene graphs using a teacher MLM and a carefully designed filtering process to ensure high-quality.
To generate more accurate and rich scene graphs at scale for any image, we introduce SG-EDIT: a self-distillation framework where GPT-4o further refines ![]() ROBIN's predicted scene graphs by removing unlikely relations and/or suggesting relevant ones. In total, our dataset contains 146K images and 5.6M relationships for 2.6M objects.
ROBIN's predicted scene graphs by removing unlikely relations and/or suggesting relevant ones. In total, our dataset contains 146K images and 5.6M relationships for 2.6M objects.
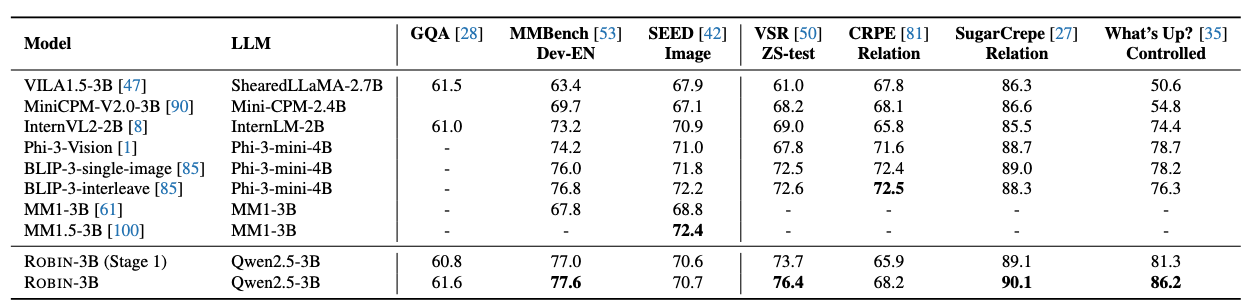
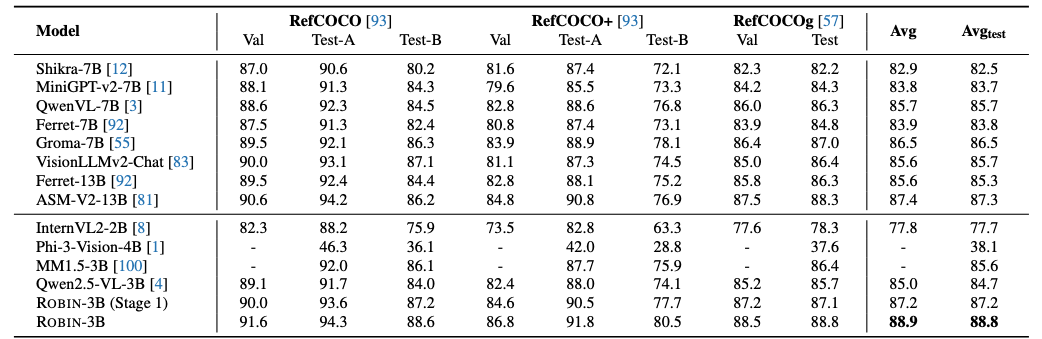
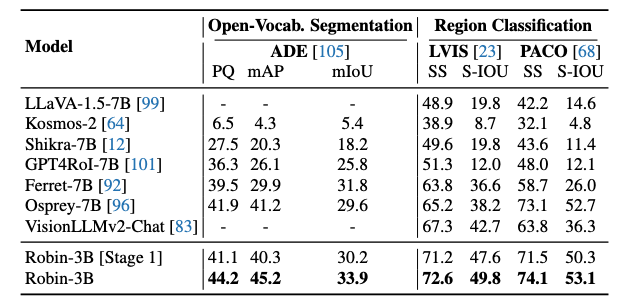
Results show that our ![]() ROBIN-3B model, despite being trained on less than 3 million instances, outperforms similar-size models trained on over 300 million instances on relationship understanding benchmarks, and even surpasses larger models up to 13B parameters. Notably, it achieves state-of-the-art performance in referring expression comprehension with a score of 88.9, surpassing the previous best of 87.4.
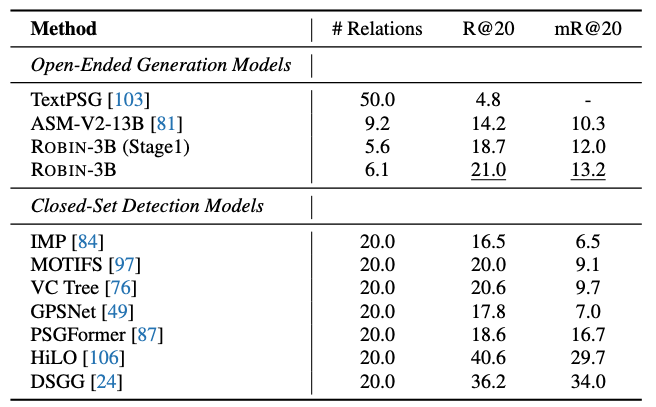
Our results suggest that training on the refined scene graph data is crucial to maintaining high performance across diverse visual reasoning tasks.
ROBIN-3B model, despite being trained on less than 3 million instances, outperforms similar-size models trained on over 300 million instances on relationship understanding benchmarks, and even surpasses larger models up to 13B parameters. Notably, it achieves state-of-the-art performance in referring expression comprehension with a score of 88.9, surpassing the previous best of 87.4.
Our results suggest that training on the refined scene graph data is crucial to maintaining high performance across diverse visual reasoning tasks.
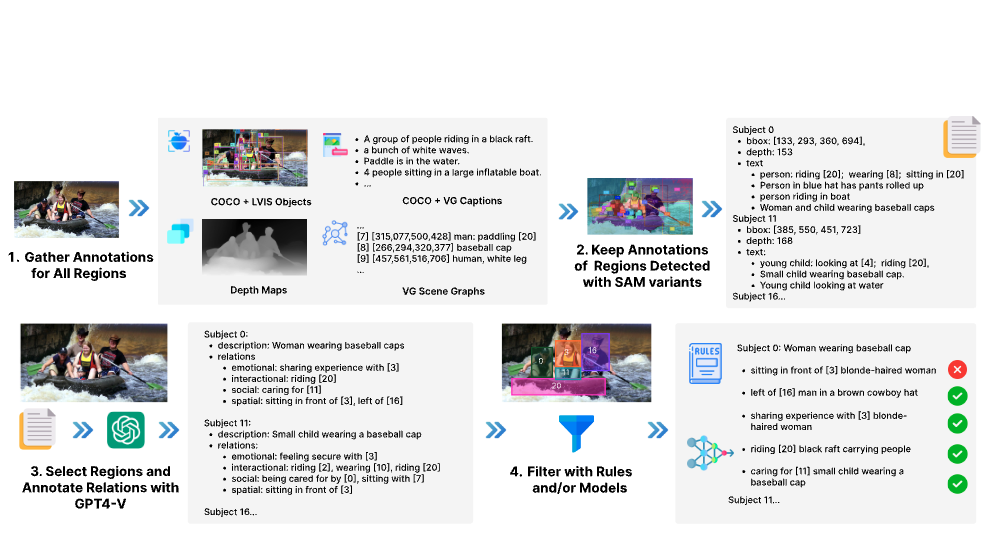
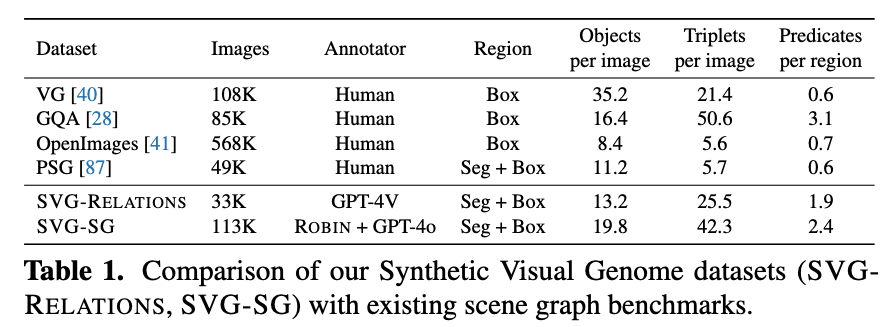
![]() SVG is created through a systematic two-stage pipeline that leverages powerful multimodal models to generate dense, high-quality scene graph annotations at scale. Our approach addresses the limitations of existing scene-graph datasets that typically lack dense and diverse relationship annotations.
SVG is created through a systematic two-stage pipeline that leverages powerful multimodal models to generate dense, high-quality scene graph annotations at scale. Our approach addresses the limitations of existing scene-graph datasets that typically lack dense and diverse relationship annotations.
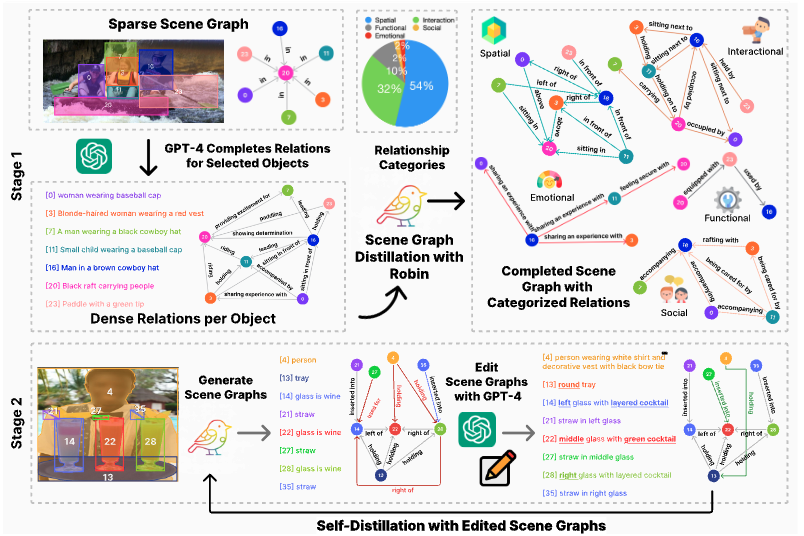
Two-Stage Pipeline: Our data generation process gradually enriches and refines scene graph annotations through dense relationship completion followed by GPT-4o editing.
Stage 1 - Dense Relationship Completion: Starting with 33K COCO images with comprehensive annotations,
we use GPT-4V to generate categorized relationships (spatial, interactional, functional, social, emotional)
for selected prominent objects, creating SVG-Relations with high-quality seed data.
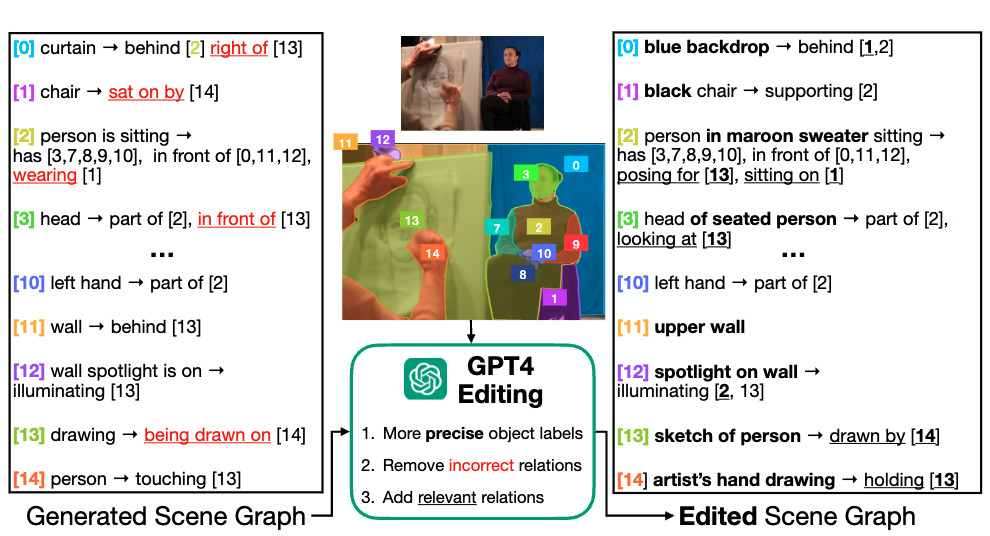
Stage 2 - SG-EDIT Distillation: We train ![]() ROBIN on SVG-Stage1,
ROBIN on SVG-Stage1,
then use it to generate scene graphs for 113K additional images from ADE20K, PSG, and Visual Genome.
GPT-4o refines these by removing incorrect relationships and adding relevant ones, creating SVG-SG.
Our final datasets consist of:
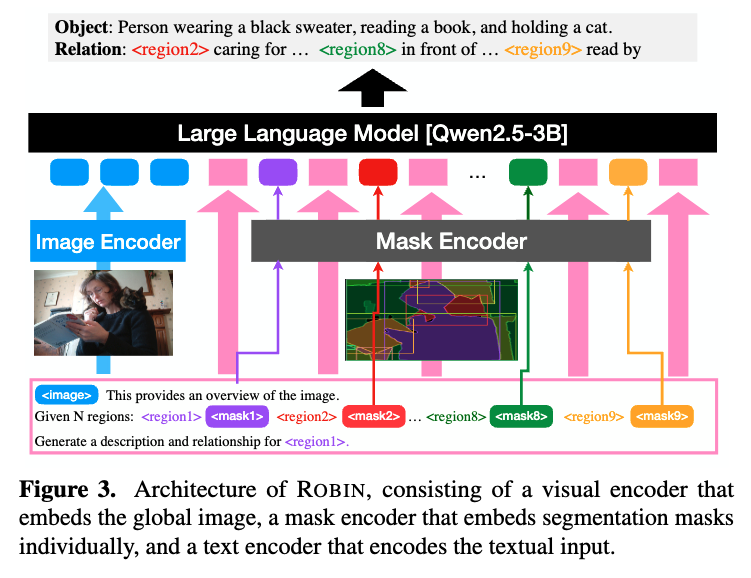
ROBIN-3B Architecture: Our model consists of three main components: (1) a ConvNext-Large vision encoder that processes the entire image into image tokens, (2) a pixel-level mask-aware extractor that embeds segmentation masks into mask tokens, and (3) a Qwen2.5-3B language model that processes image, mask, and text tokens. This dual representation (pixel-level masks + text coordinates) enables precise, fine-grained localization, handling up to 99 regions per image with LLM's 8K context window.

Rich Relationship Diversity: Captures spatial (in front of, standing next to), social (married to), emotional (happy with), and interactional (hugging, cutting) relationships with detailed object descriptions like "three-tiered cake with fruit on top."

Role & Action Understanding: Accurately identifies competing players (batter vs pitcher), spectators watching in background, and small objects like sports ball in air with correct action relationships (thrown by, preparing to hit).

Part-Whole Relationships: Precisely identifies vehicle components (dashboard, door, front wheel, handle) as parts of cars and distinguishes spatial markers like "left taillight" vs "right taillight" in cluttered automotive scenes.
@inproceedings{park2025svg,
author = {Park, Jae Sung and Ma, Zixian and Li, Linjie and Zheng, Chenhao and Hsieh, Cheng-Yu and Lu, Ximing and Chandu, Khyathi and Kong, Quan and Kobori, Norimasa and Farhadi, Ali and Choi, Yejin and Krishna, Ranjay},
title = {Synthetic Visual Genome: Dense Scene Graphs at Scale with Multimodal Language Models},
booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2025}
}


